Building Clean, Maintainable vLLM Modifications Using the Plugin System
[!NOTE] Originally posted on this Medium article. Source: https://github.com/vllm-project/vllm-ascend A...
vLLM is a fast and easy-to-use library for LLM inference and serving.
[!NOTE] Originally posted on this Medium article. Source: https://github.com/vllm-project/vllm-ascend A...
The earlier versions of vLLM Semantic Router relied on classification-based routing, a straightforward approach where...
Expanding Docker Model Runner’s Capabilities Today, we’re excited to announce that Docker Model Runner now integrate...
[!NOTE] Originally posted on the Cohere blog. Introducing Shared Memory IPC Caching — a high-performance caching...
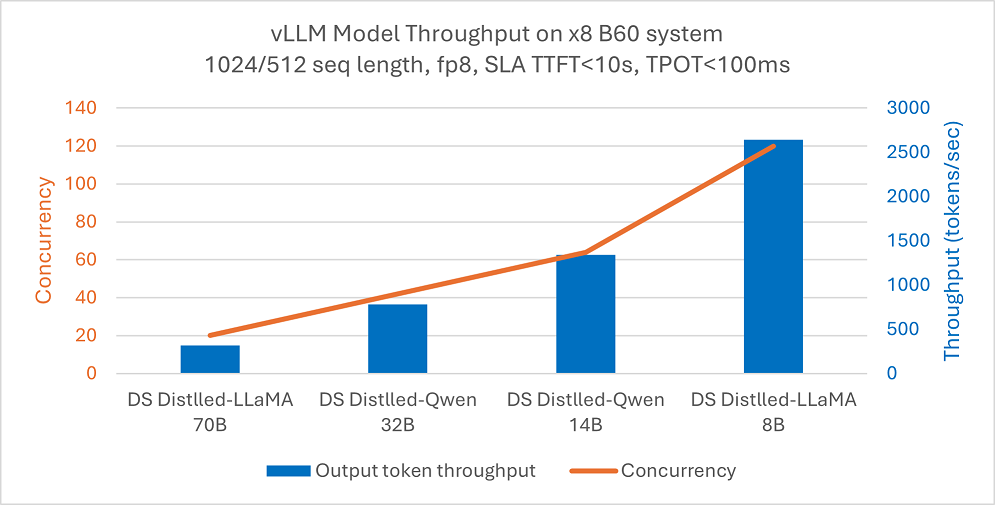
Intel® Arc™ Pro B-Series GPU Family GPUs deliver powerful AI capabilities with a focus on accessibility and exception...
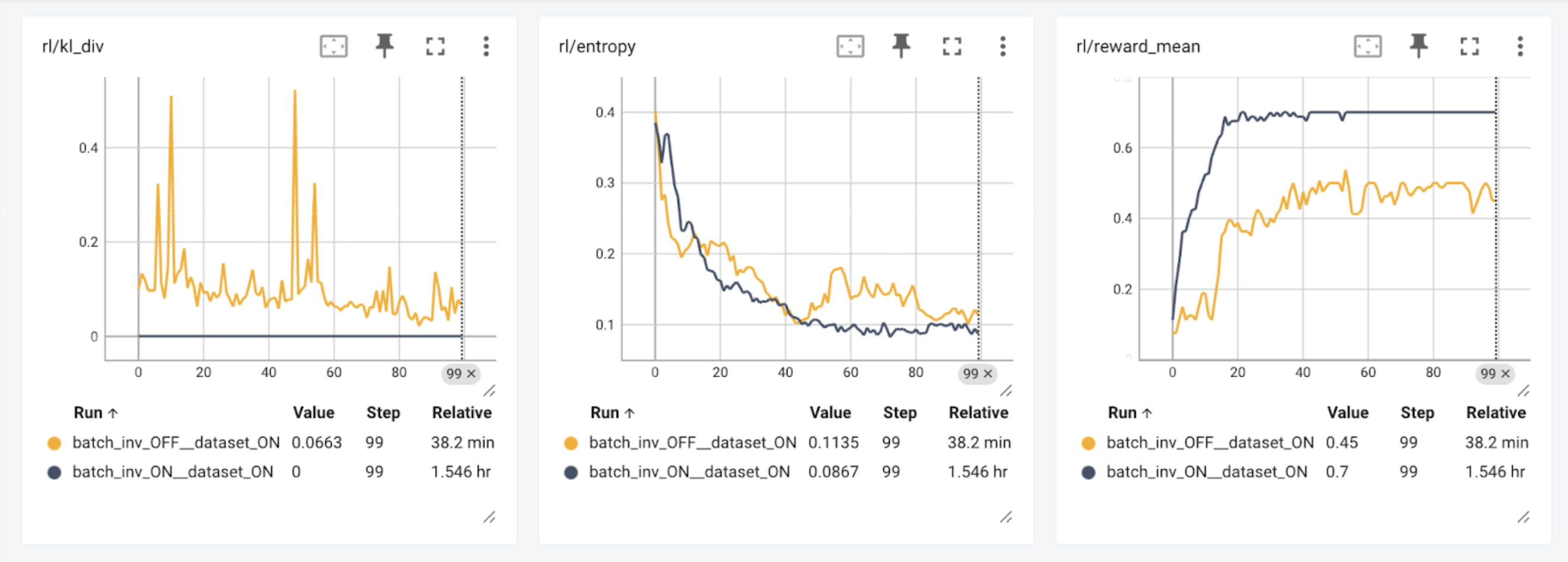
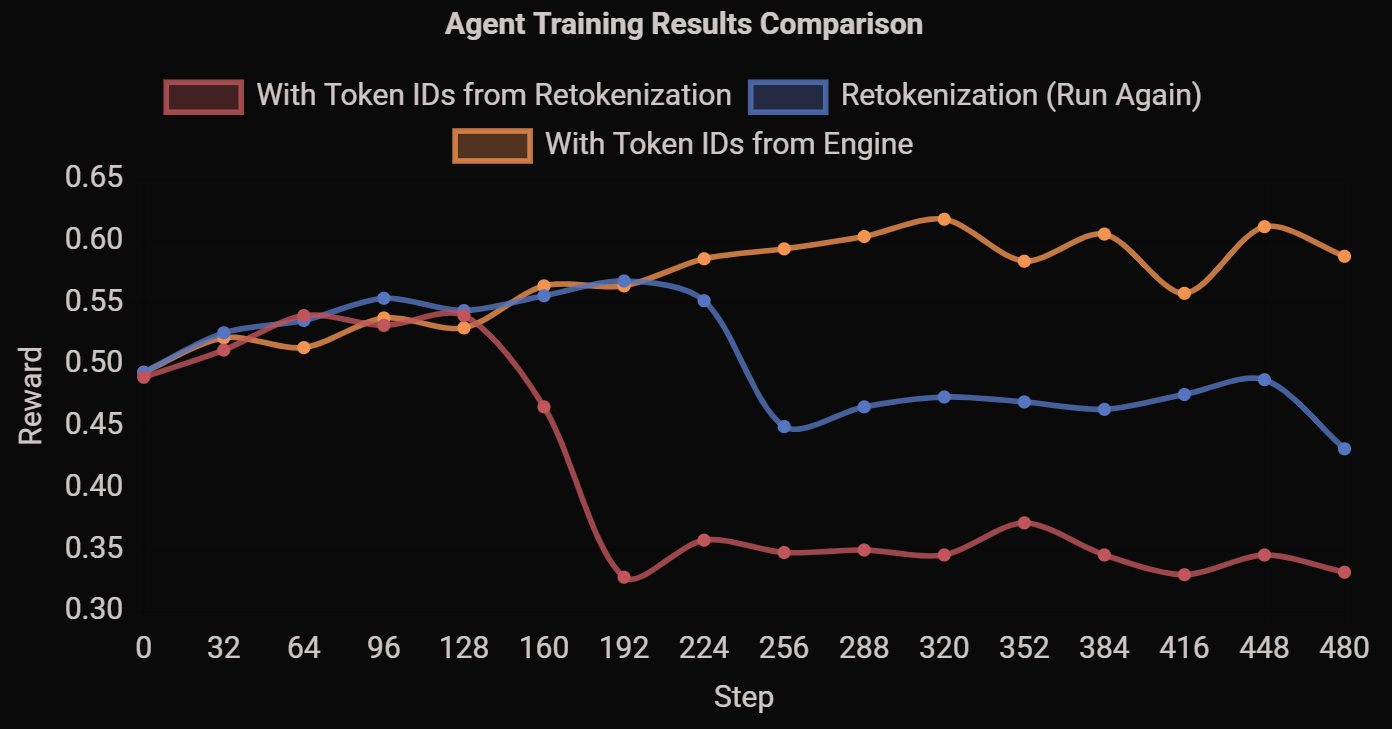
We demonstrate an open-source bitwise consistent on-policy RL run with TorchTitan as the training engine and vLLM as ...
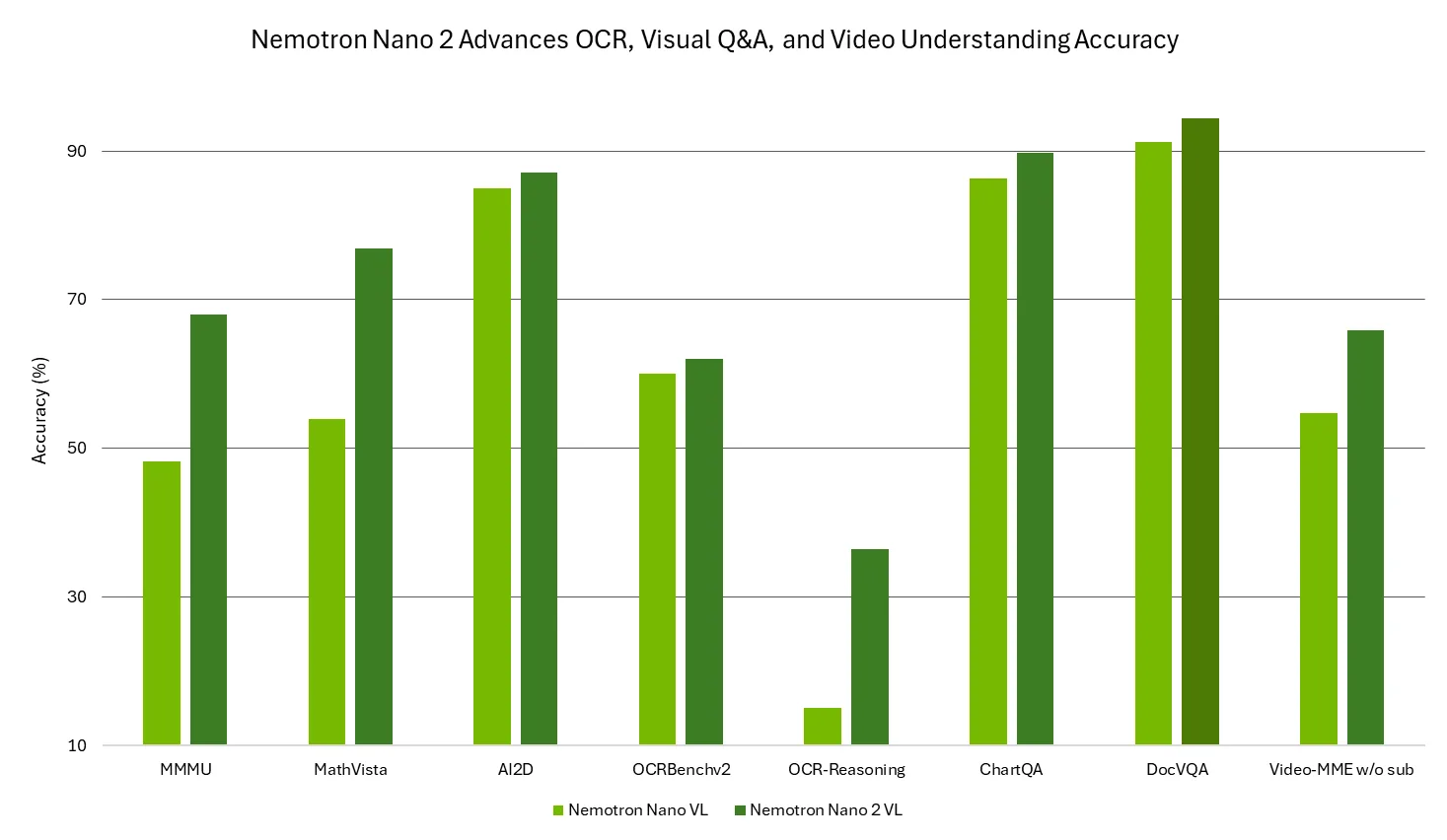
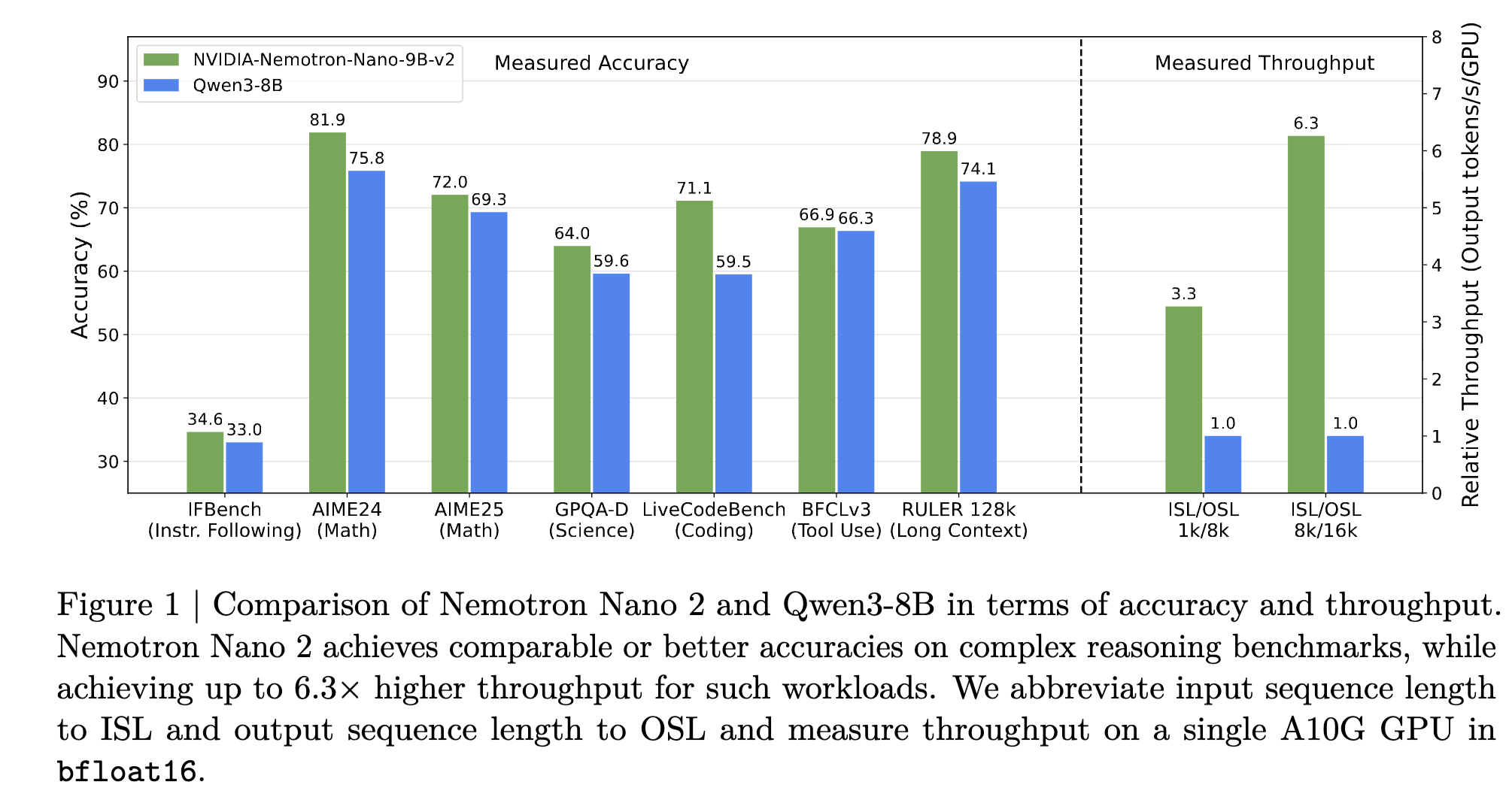
We are excited to release NVIDIA Nemotron Nano 2 VL, supported by vLLM. This open vision language model (VLM) is buil...
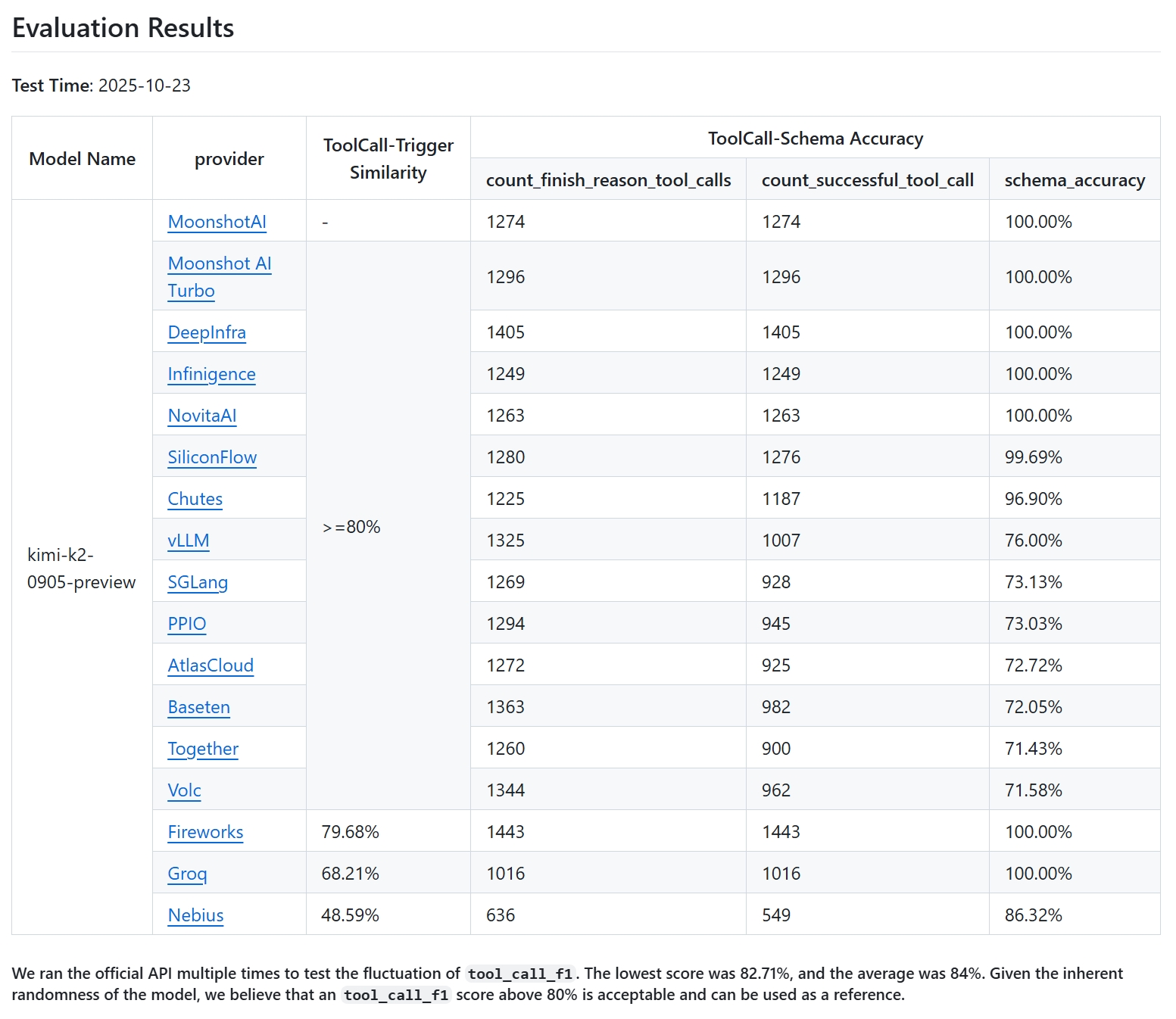
TL;DR: For best compatibility with vLLM, use Kimi K2 models whose chat templates were updated after commit 94a4053eb8...
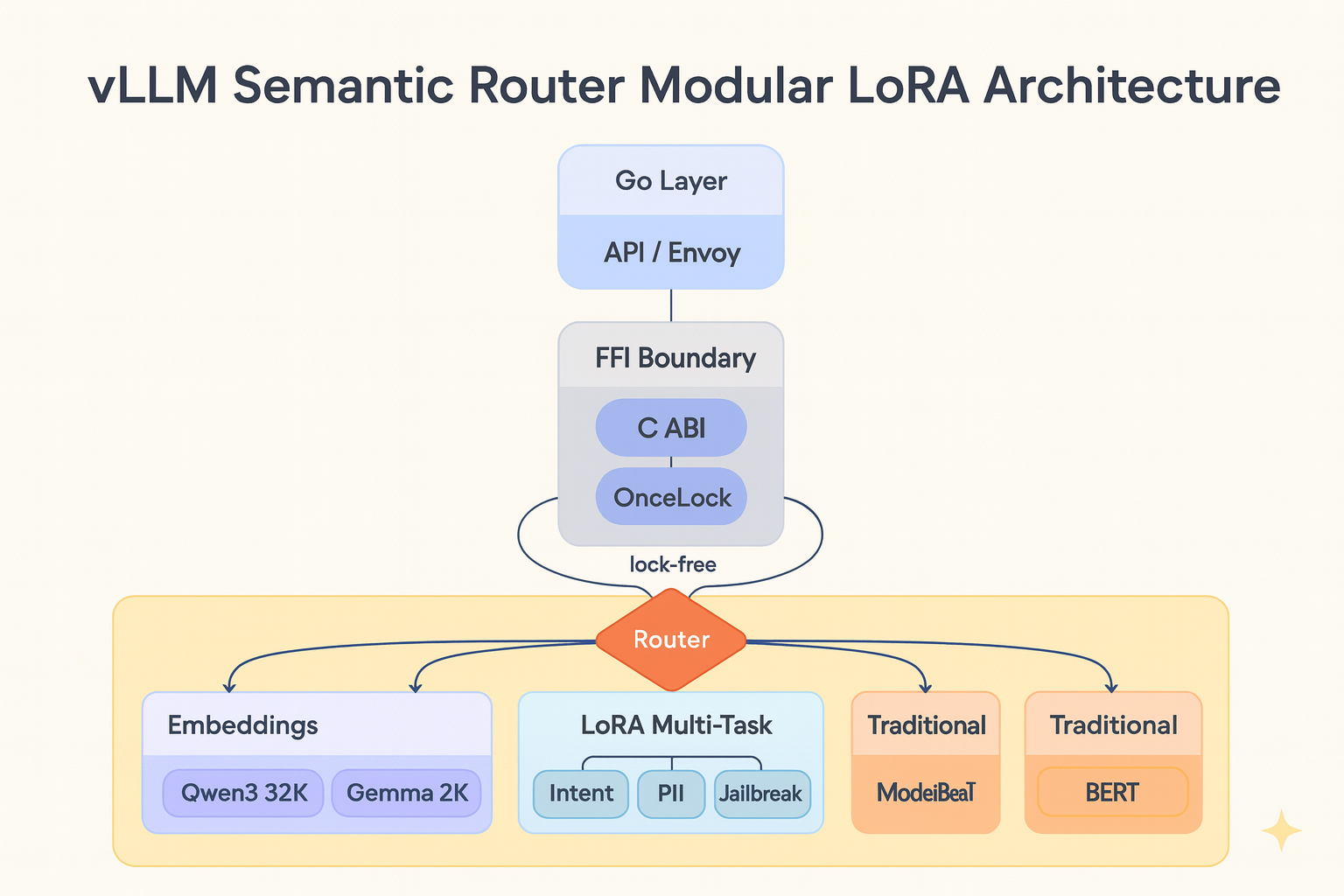
Semantic routing systems face a scaling challenge. When each classification request requires running multiple fine-tu...

Introduction The multi-model serving problem: You have two LLMs that each fit on your GPU, but not both at once. Tra...
Agentic AI systems, capable of reasoning, planning, and taking autonomous actions, are powering the next leap in deve...
TL;DR. Agent often calls LLMs via OpenAI‑compatible endpoints, which previously return only string-based inputs and o...

vLLM TPU is now powered by tpu-inference, an expressive and powerful new hardware plugin unifying JAX and PyTor...
Introduction Over the past several months, we’ve been collaborating closely with NVIDIA to unlock the full potential...

Introduction We are excited to announce Day 0 support for DeepSeek-V3.2-Exp, featuring DeepSeek Sparse Attention (DS...

The first vLLM meetup in Korea was held on August 19, 2025, in Seoul, hosted by Rebellions and Red Hat with sup...
Industry Status: Inference ≠ More Is Better Over the past year, hybrid reasoning and automatic routing have increa...

We’re excited to announce that vLLM now supports Qwen3-Next, the latest generation of foundation models from the Qwen...
Introduction Until recently, generative AI infrastructure has been tightly coupled with autoregressive text generati...
[!NOTE] Originally posted on Aleksa Gordic’s website. From paged attention, continuous batching, prefix caching,...
[!NOTE] This blog originated from our biweekly vLLM office hours, a community forum hosted by Red Hat with vLLM pr...
Introduction General Language Model (GLM) is a family of foundation models created by Zhipu.ai (now renamed to Z.ai)...
TL;DR: If you hit an illegal memory access was encountered error, you can enable CUDA core dump to debug the issue. S...
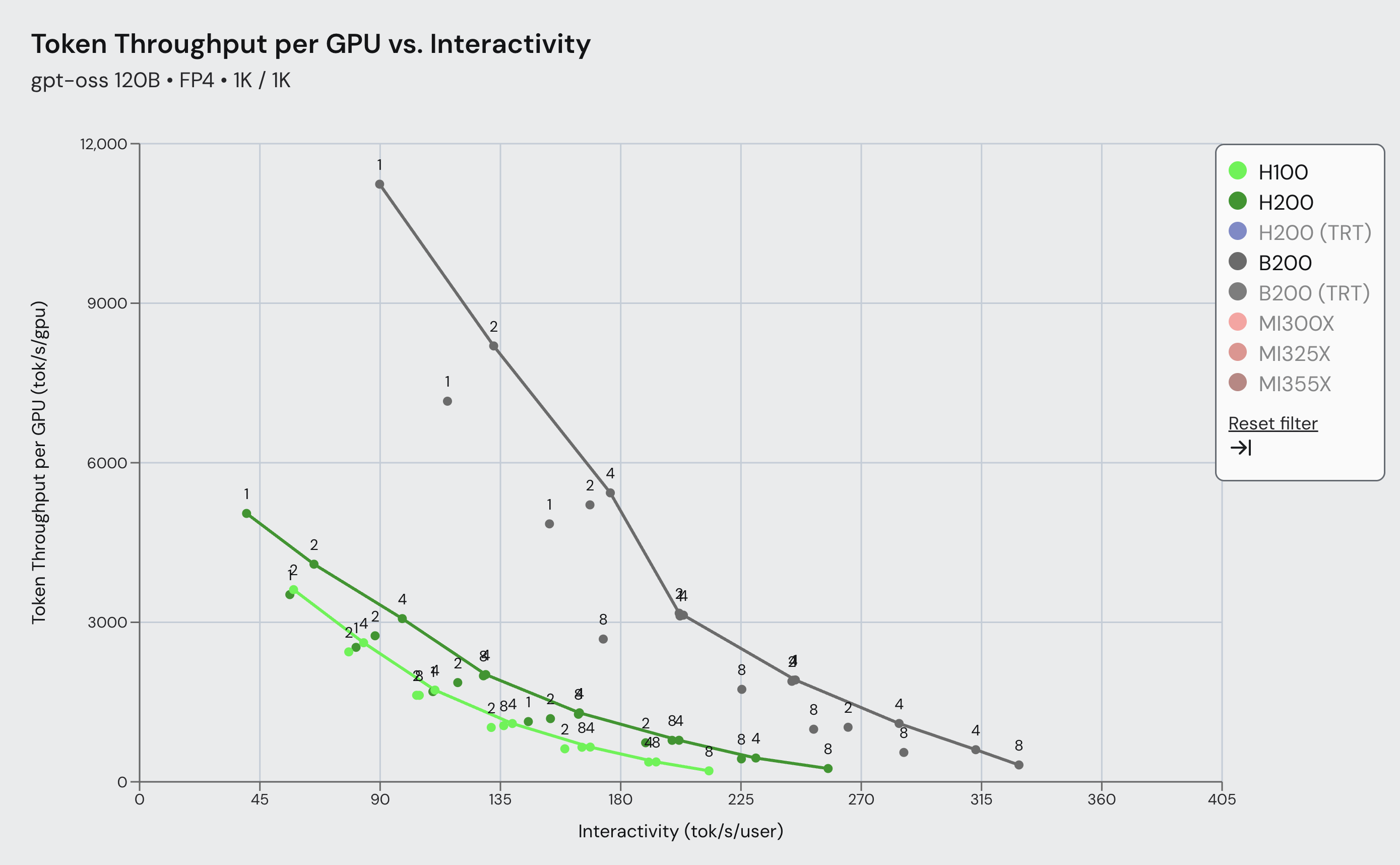
We’re thrilled to announce that vLLM now supports gpt-oss on NVIDIA Blackwell and Hopper GPUs, as well as AMD MI300x ...
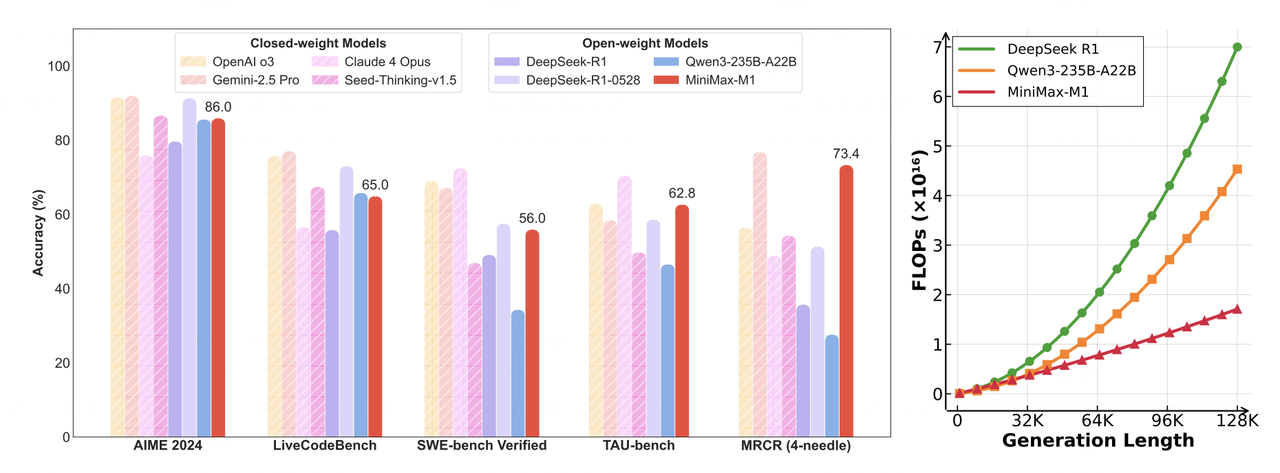
This article explores how MiniMax-M1’s hybrid architecture is efficiently supported in vLLM. We discuss the model’s u...
Since December 2024, through the joint efforts of the vLLM community and the Ascend team on vLLM, we have completed t...
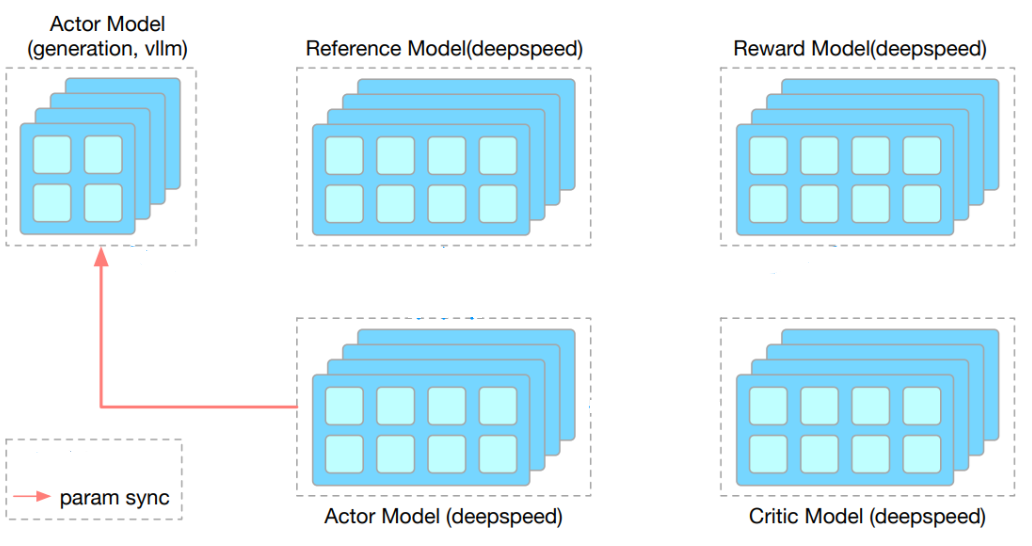
As demand grows for training reasoning-capable large language models (LLMs), Reinforcement Learning from Human Feedba...

The Hugging Face Transformers library offers a flexible, unified interface to a vast ecosystem of model architectures...
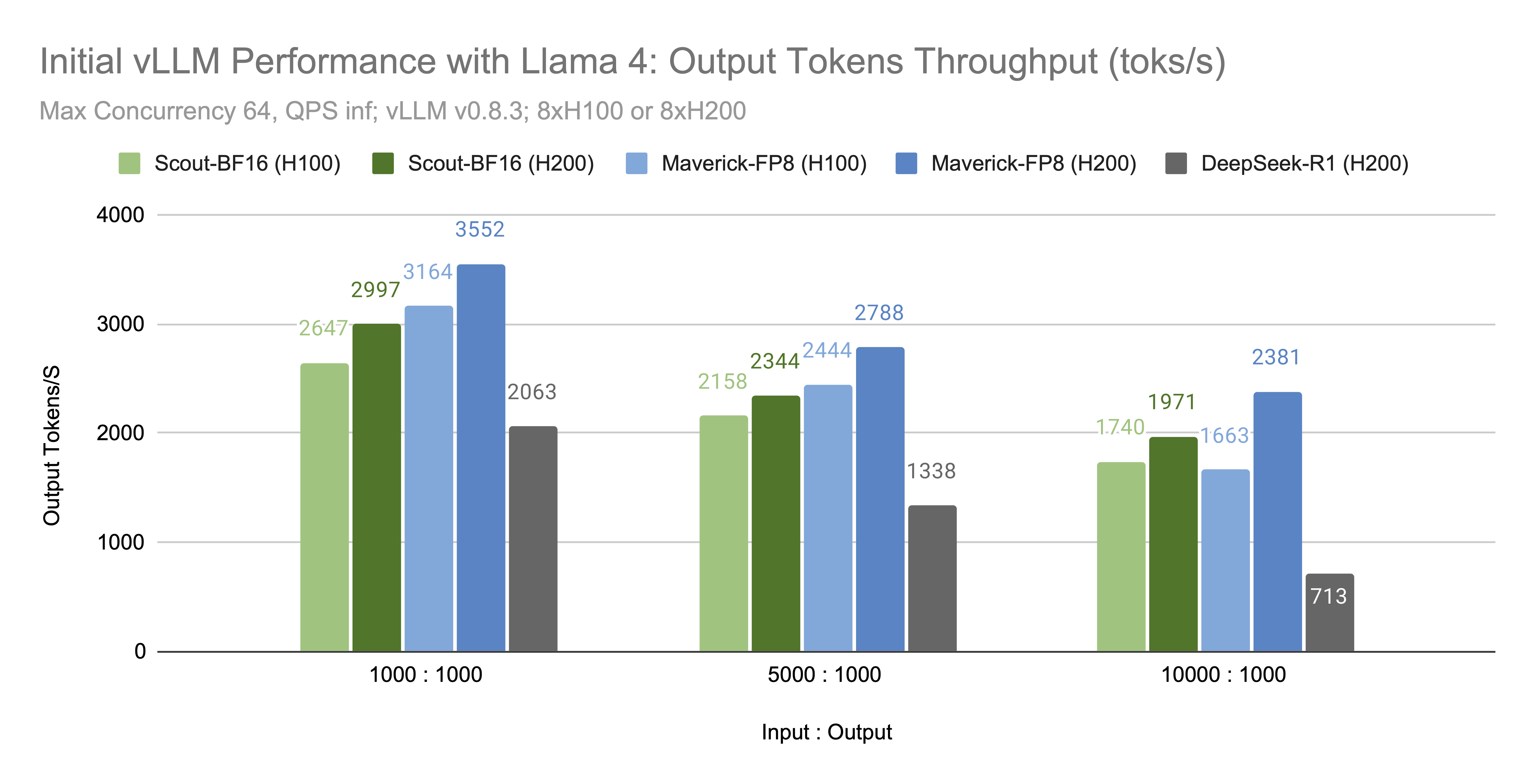
We’re excited to announce that vLLM now supports the Llama 4 herd of models: Scout (17B-16E) and Maverick (17B-128E)....

TL;DR: vLLM on AMD ROCm now has better FP8 performance! What’s new? PTPC-FP8 quantization is now supported in vLL...
Today, we are excited to announce vllm-project/aibrix: a battery-included vLLM Kubernetes serving stack developed by ...
Motivation Serving large models often leads to memory bottlenecks, such as the dreaded CUDA out of memory error. To ...
We are thrilled to announce the alpha release of vLLM V1, a major upgrade to vLLM’s core architecture. Based on...
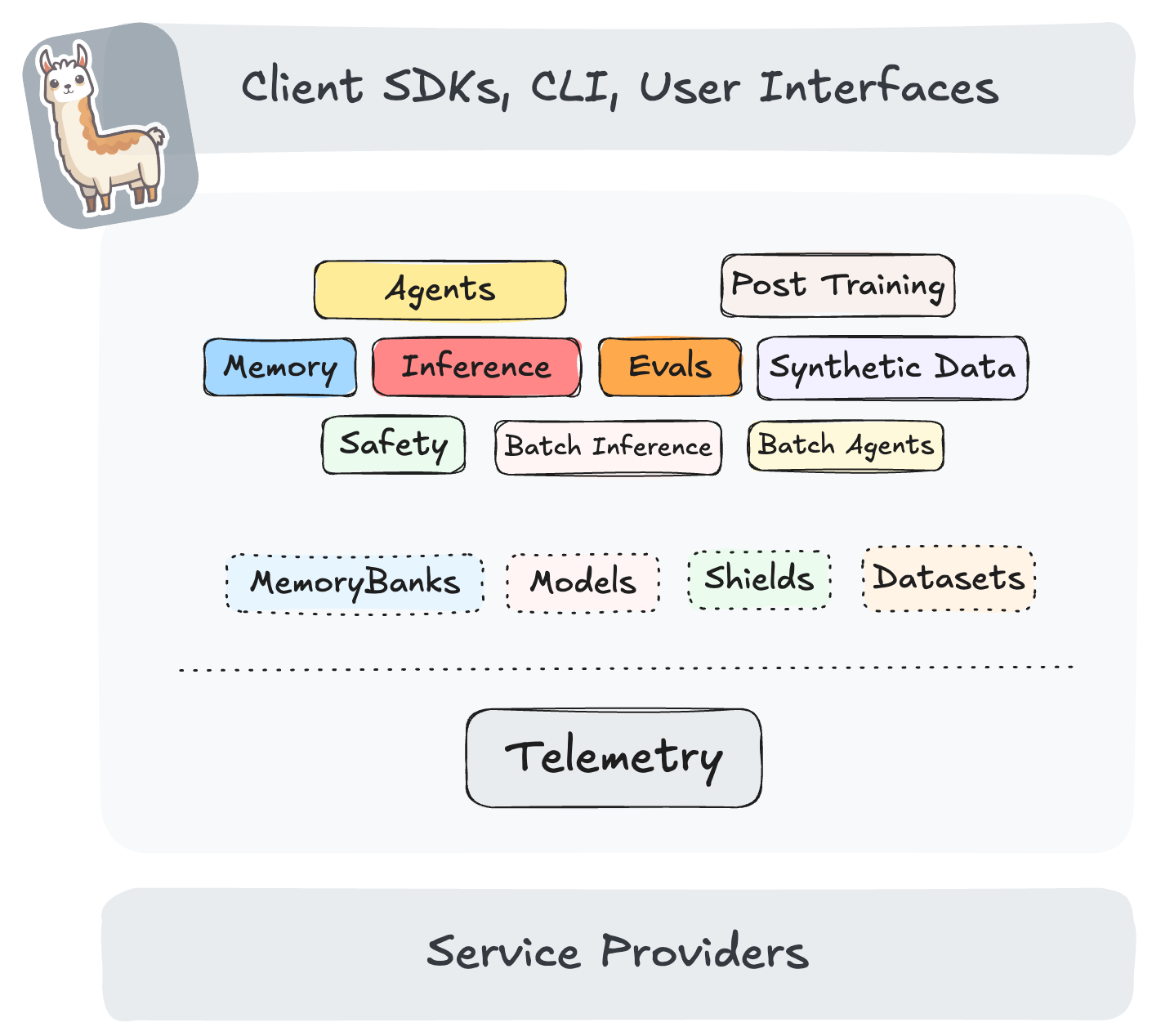
We are excited to announce that vLLM inference provider is now available in Llama Stack through the collaboration bet...
TL;DR vLLM boasts the largest open-source community, but what does it take to transform vLLM from the best singl...
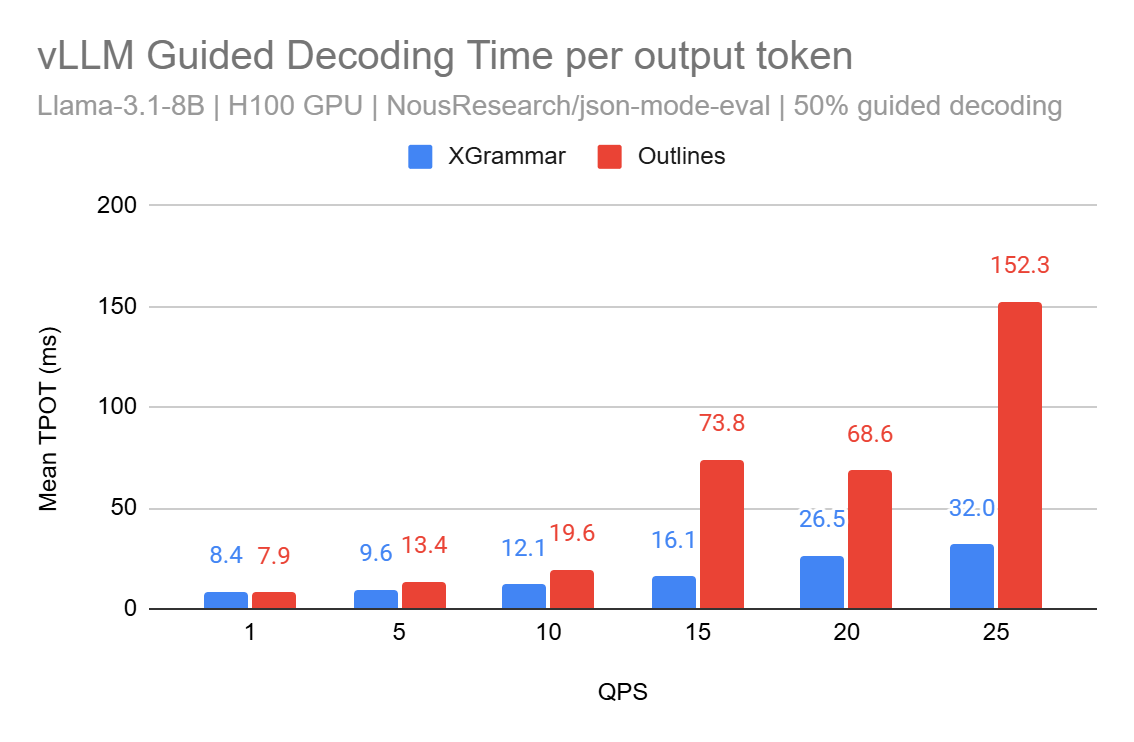
TL/DR: Structured decoding allows precise control over LLM output formats vLLM now supports both outlines and X...
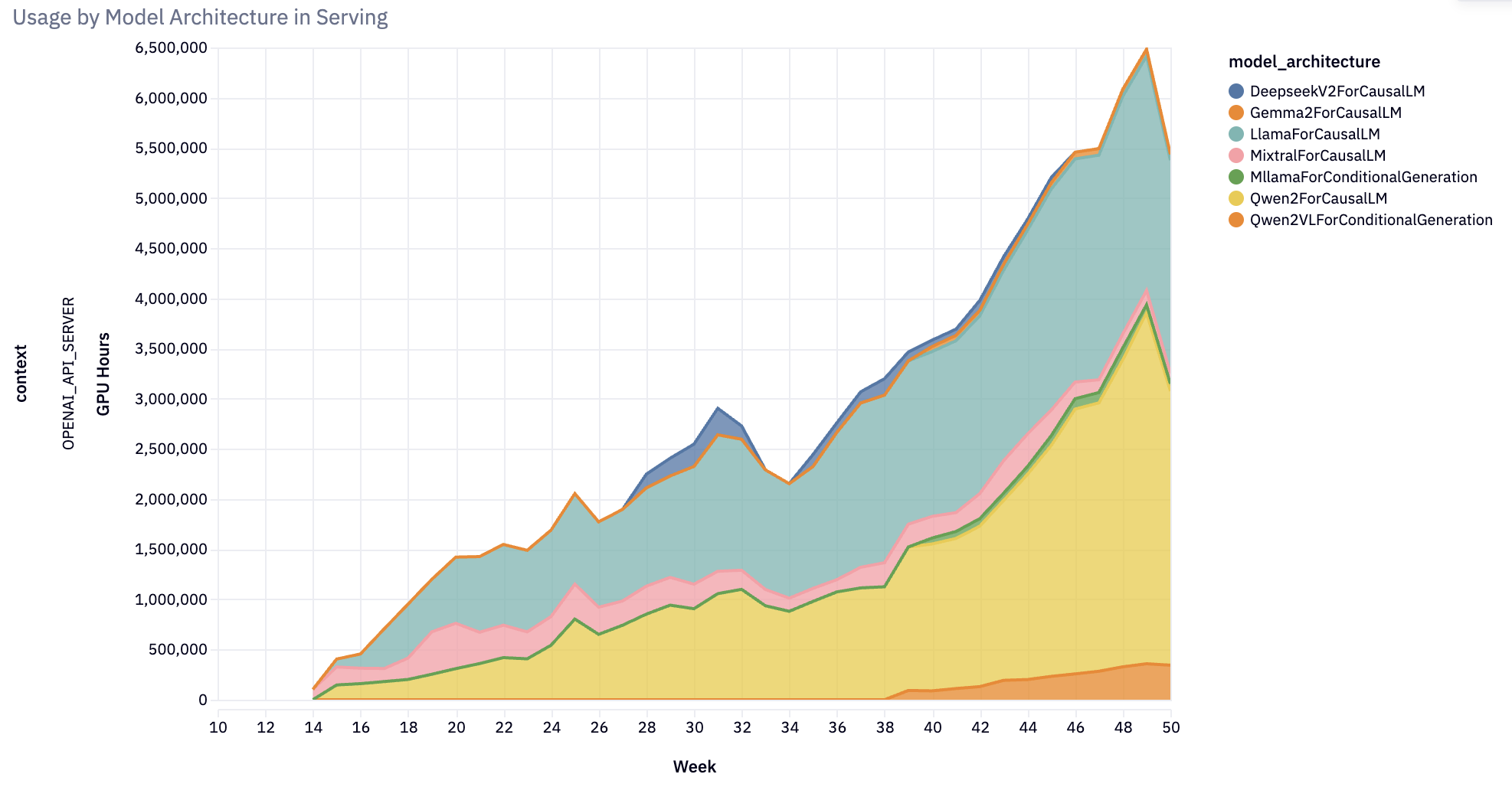
The vLLM community achieved remarkable growth in 2024, evolving from a specialized inference engine to become the de ...
The field of LLM inference is advancing at an unprecedented pace. With new models and features emerging weekly, the t...
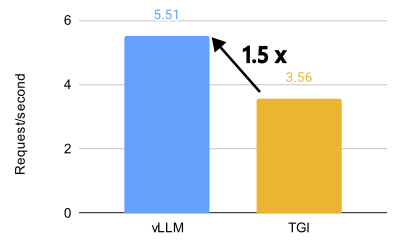
TL;DR: vLLM unlocks incredible performance on the AMD MI300X, achieving 1.5x higher throughput and 1.7x faster time-t...
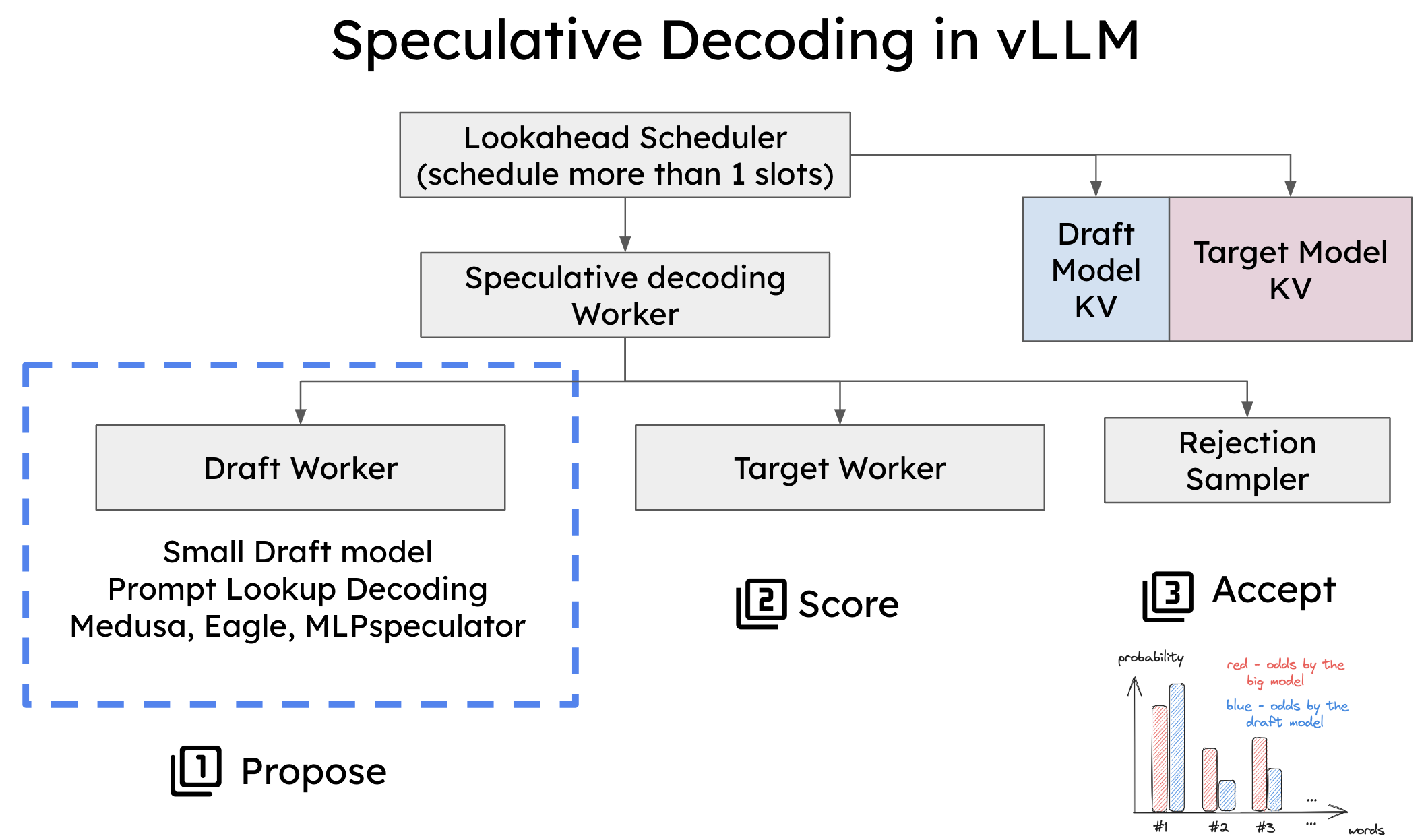
Speculative decoding in vLLM is a powerful technique that accelerates token generation by leveraging both small and l...
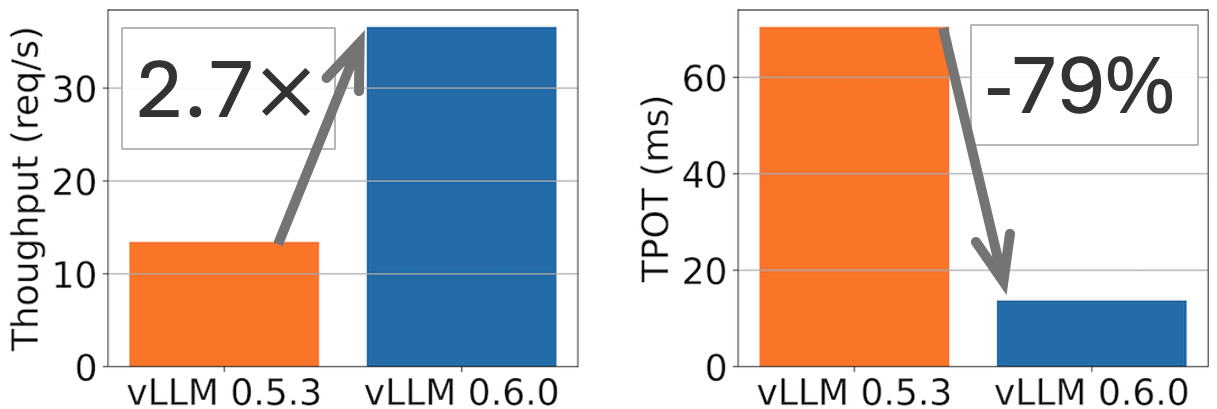
TL;DR: vLLM achieves 2.7x higher throughput and 5x faster TPOT (time per output token) on Llama 8B model, and 1.8x hi...
We would like to share two updates to the vLLM community. Future of vLLM is Open We are excited to see vLLM i...
Today, the vLLM team is excited to partner with Meta to announce the support for the Llama 3.1 model series. Llama 3....
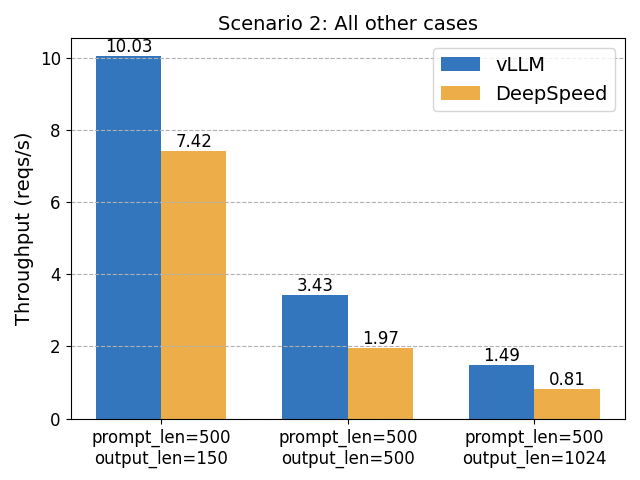
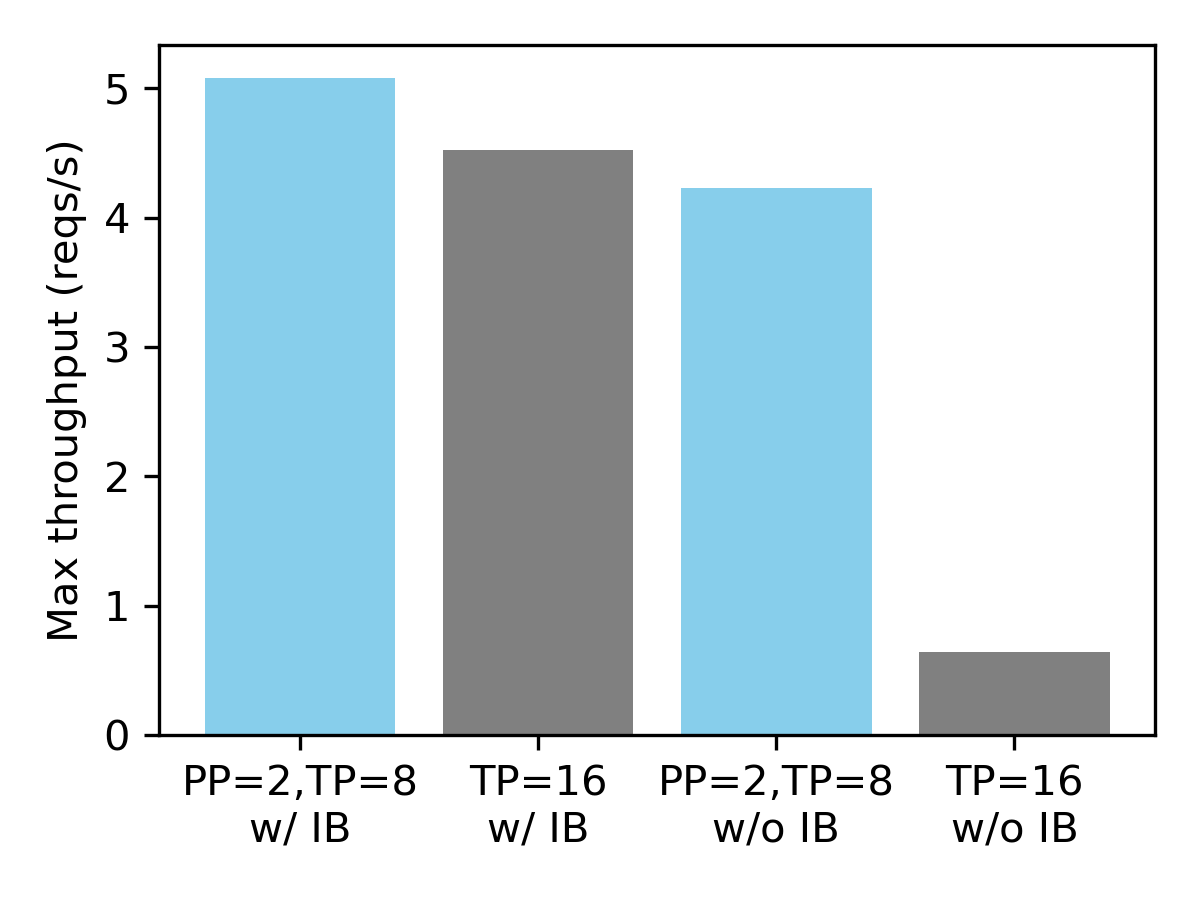
TL;DR: vLLM matches DeepSpeed-FastGen’s speed in common scenarios and surpasses it when handling longer outputs....
GitHub | Documentation | Paper LLMs promise to fundamentally change how we use AI across all industries. However, ...