TL;DR
- vLLM boasts the largest open-source community, but what does it take to transform vLLM from the best single-node LLM engine to a premier LLM serving system?
- Today, we release “vLLM production-stack”, a vLLM-based full inference stack that introduces two major advantages:
- 10x better performance (3-10x lower response delay & 2-5x higher throughput) with prefix-aware request routing and KV-cache sharing.
- Easy cluster deployment with built-in support for fault tolerance, autoscaling, and observability.
- And the best part? It’s open-source—so everyone can get started right away! [https://github.com/vllm-project/production-stack]
The Context
In the AI arms race, it’s no longer just about who has the best model—it’s about who has the best LLM serving system.
vLLM has taken the open-source community by storm, with unparalleled hardware and model support plus an active ecosystem of top-notch contributors. But until now, vLLM has mostly focused on single-node deployments.
How do we extend its power into a full-stack inference system that any organization can deploy at scale with high reliability, high throughput, and low latency? That’s precisely why the LMCache team and the vLLM team built vLLM production-stack.
Introducing “vLLM Production-Stack”
vLLM Production-stack is an open-source reference implementation of an inference stack built on top of vLLM, designed to run seamlessly on a cluster of GPU nodes. It adds four critical functionalities that complement vLLM’s native strengths:
- KV cache sharing & storage to speed up inference when context is reused (powered by the LMCache project).
- Prefix-aware routing that sends queries to the vLLM instance already holding the relevant context KV cache.
- Observability of individual engine status and query-level metrics (TTFT, TBT, throughput).
- Autoscaling to handle dynamics of workloads.
Comparison with Alternatives:
Below is a quick snapshot comparing vLLM production-stack with its closest counterparts:

The Design
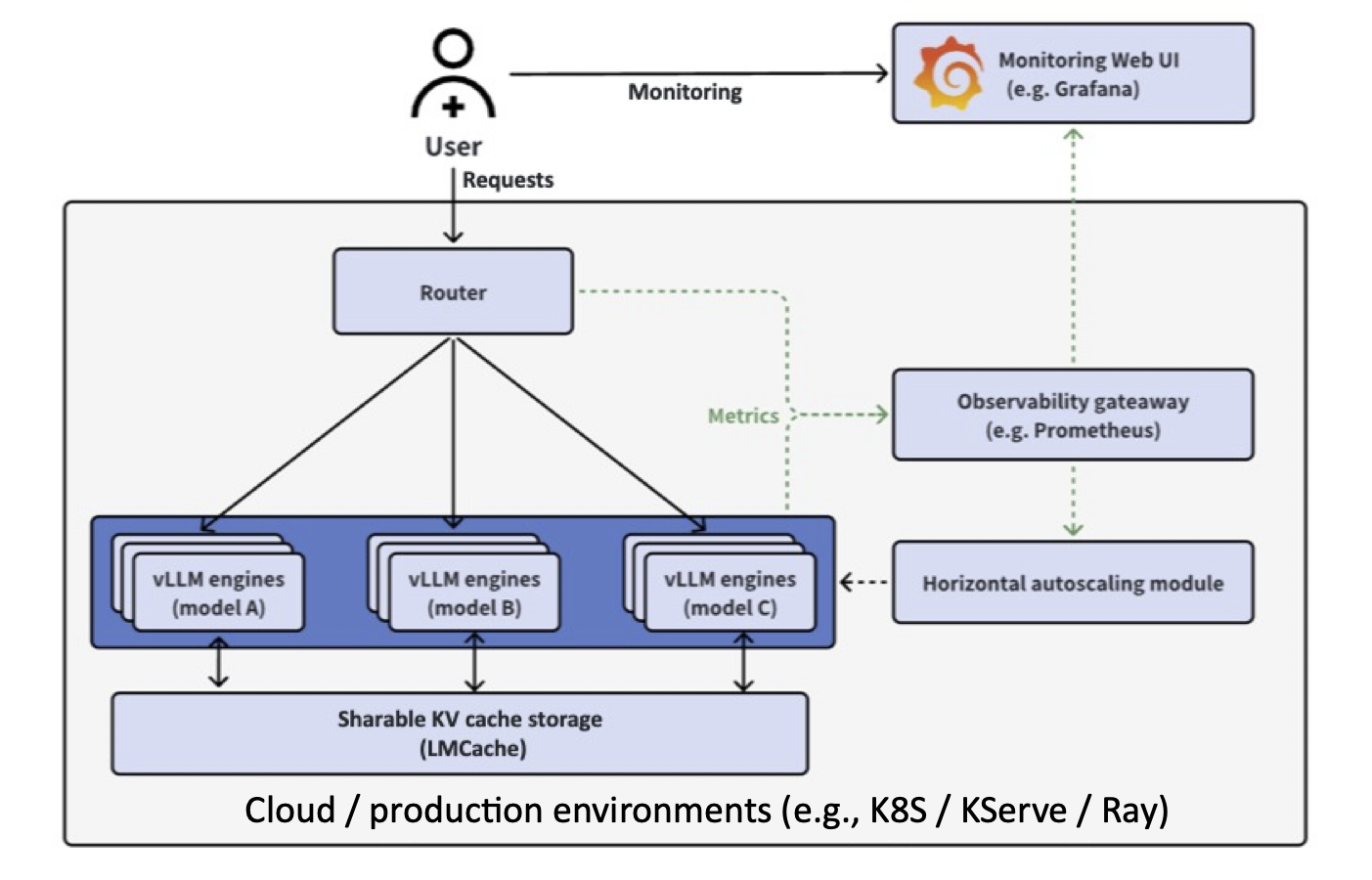
The vLLM production-stack architecture builds on top of vLLM’s powerful single-node engine to provide a cluster-wide solution.
At a high level:
- Applications send LLM inference requests.
- Prefix-aware routing checks if the requested context is already cached within the memory pool of one instance. It then forwards the request to the node with the pre-computed cache.
- Autoscaling and a cluster manager watch the overall load and spin up new vLLM nodes if needed.
- Observability modules gather metrics like TTFT (Time-To-First-Token), TBT (Time-Between-Tokens), and throughput, giving you real-time insights into your system’s health.
Advantage #1: Easy Deployment
Use helm chart to deploy the vLLM production-stack to your k8s cluster through running a single command:
sudo helm repo add llmstack-repo https://lmcache.github.io/helm/ &&\
sudo helm install llmstack llmstack-repo/vllm-stack
For more details, please refer to the detailed README at vLLM production-stack repo. Tutorials about setting up k8s cluster and customizing helm charts are also available.
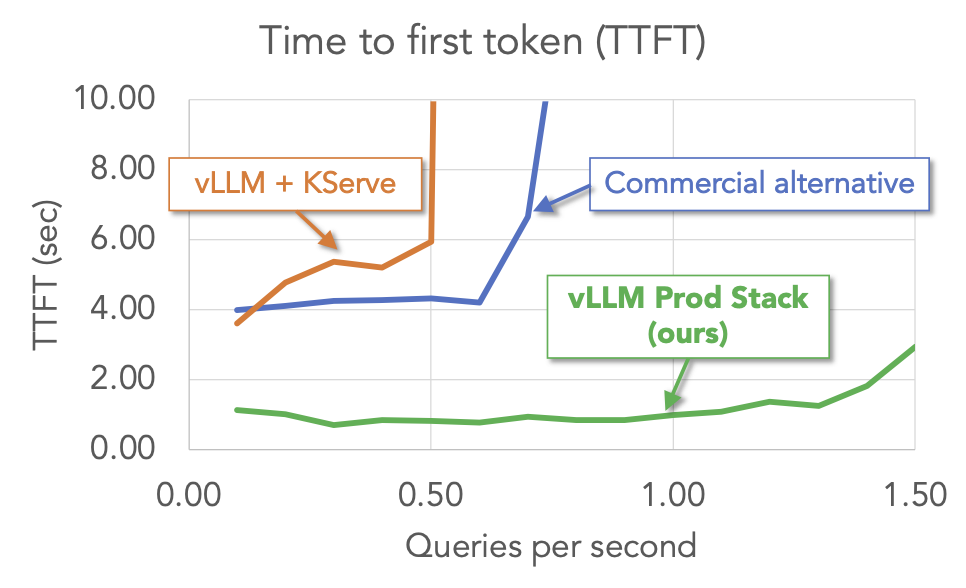
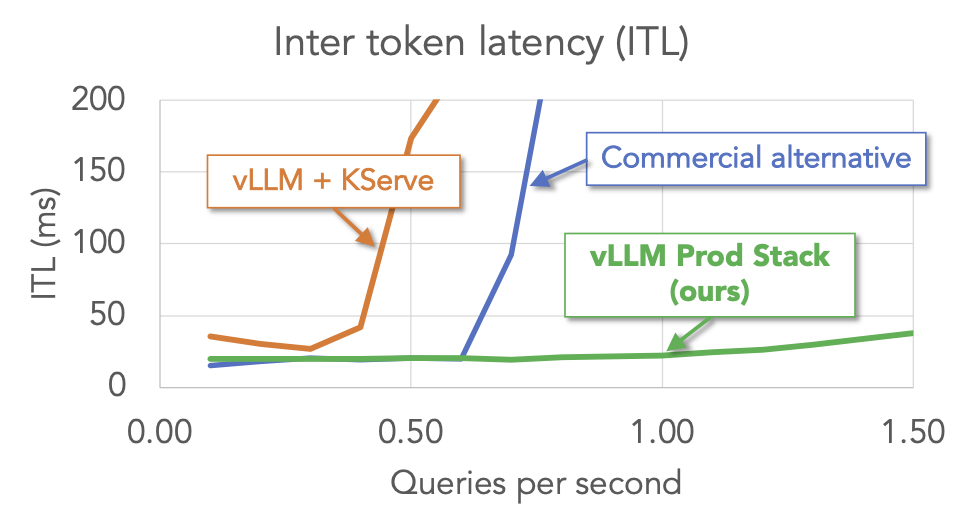
Advantage #2: Better Performance
We conduct a benchmark of multi-round Q&A workload on vLLM production-stack and other setups, including vLLM + KServe and an commercial endpoint service. The results show vLLM stack outperforms other setups across key metrics (time to first token and inter token latency).
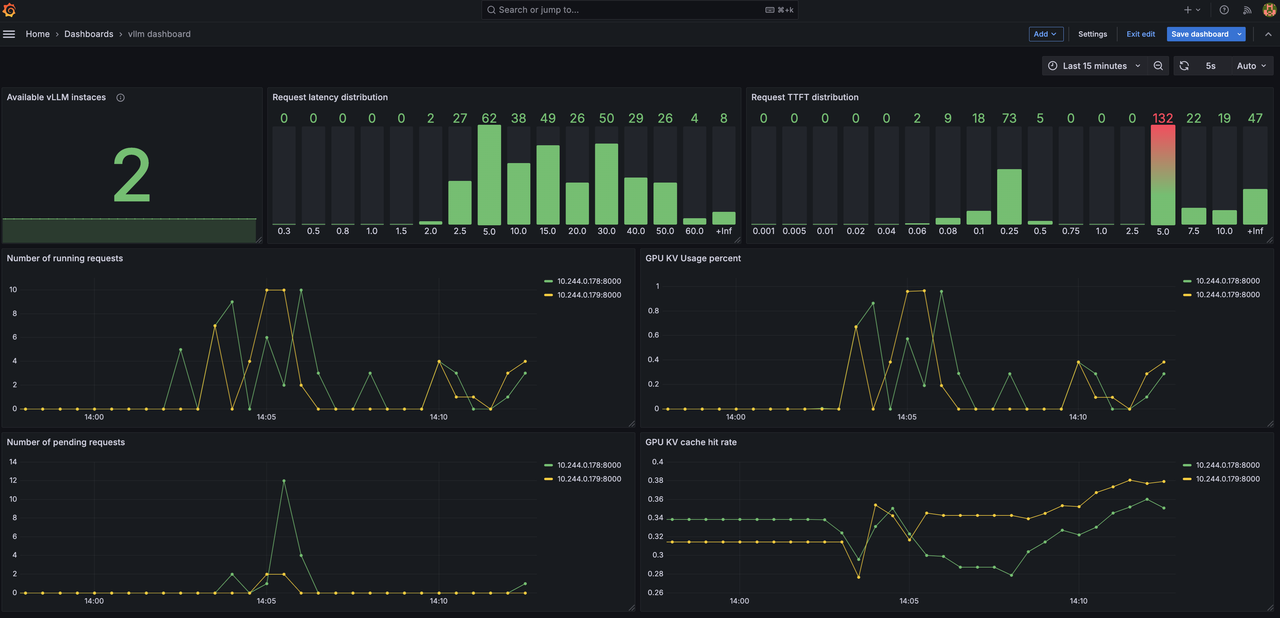
Advantage #3: Effortless Monitoring
Keep real-time tracking of your LLM inference cluster with key metrics including latency distributions, number of requests over time, KV cache hit rate.
Conclusion
We’re thrilled to unveil vLLM Production Stack—the next step in transforming vLLM from a best-in-class single-node engine into a full-scale LLM serving system. We believe the vLL stack will open new doors for organizations seeking to build, test, and deploy LLM applications at scale without sacrificing performance or simplicity.
If you’re as excited as we are, don’t wait!
- Clone the repo: https://github.com/vllm-project/production-stack
- Kick the tires
- Let us know what you think!
- Interest Form
Join us to build a future where every application can harness the power of LLM inference—reliably, at scale, and without breaking a sweat. Happy deploying!
Contacts: