Today, we are excited to announce vllm-project/aibrix: a battery-included vLLM Kubernetes serving stack developed by Bytedance. Started in early 2024, AIBrix has been successfully deployed to support multiple business use cases across ByteDance, demonstrating its scalability and effectiveness in large-scale deployments.
While vLLM makes deploying a single serving instance easy, deploying vLLM at scale presents unique challenges in routing, autoscaling, and fault tolerance. AIBrix is an open-source initiative designed to provide the essential building blocks to construct scalable inference infrastructure. It delivers a cloud-native solution optimized for deploying, managing, and scaling large language model (LLM) inference, tailored specifically to enterprise needs.
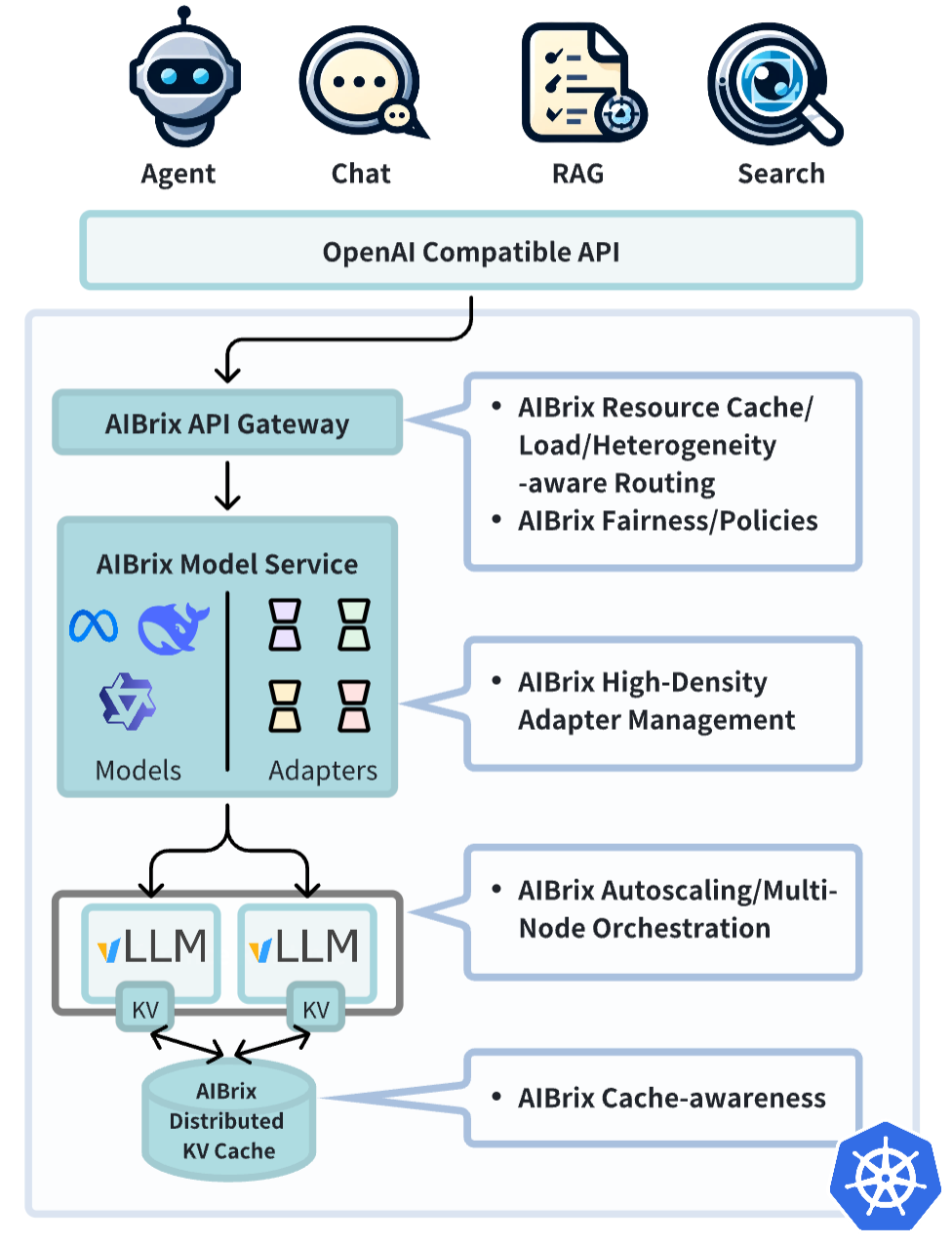
The initial release focuses on the following key features:
- High-Density LoRA Management: Streamlined support for lightweight, low-rank adaptations of models.
- LLM Gateway and Routing: Efficiently manage and direct traffic across multiple models and replicas.
- LLM App-Tailored Autoscaler: Dynamically scale inference resources based on real-time demand.
- Unified AI Runtime: A versatile sidecar enabling metric standardization, model downloading, and management.
- Distributed Inference: Scalable architecture to handle large workloads across multiple nodes.
- Distributed KV Cache: Enables high-capacity, cross-engine KV reuse.
- Cost-efficient Heterogeneous Serving: Enables mixed GPU inference to reduce costs with SLO guarantees
- GPU Hardware Failure Detection: Proactive detection of GPU hardware issues.
AIBrix Vision & Industry Collaboration
AIBrix is built on the principle of system and inference engine co-design, with a primary focus on constructing scalable inference systems on Kubernetes in a cloud-native way. Moving forward, we will continue exploring the co-design approach through initiatives such as
- Expanding distributed KV cache to support a wider range of scenarios, including Prefill & Decode (P&D) aggregation, request migration, and cross-instance KV reuse, improving memory efficiency and inference flexibility.
- Adopting traditional resource management principles like QoS, Priority, Fairness to LLM inference to enabling request-level multi-tenancy to ensure efficient resource allocation.
- Apply roofline-based profiling to optimize computational efficiency and deliver strong SLO-guaranteed inference performance across diverse workloads.
As part of this mission, we actively collaborate with industry leaders to drive open, cloud-native solutions for LLM serving.
“ByteDance has been a phenomenal partner in helping Google drive standardization of LLM serving in Kubernetes through Working Group Serving and contributing to the Gateway API Inference Extension. We are excited to continue collaborating on shared components that will enable AIBrix and large scale inference platforms” - Clayton Coleman, Distinguished Engineer and Inference Lead for GKE
“vLLM has seen explosive growth worldwide, becoming a cornerstone of LLM inference. AIBrix is a promising project that builds on this momentum, offering powerful capabilities to productionize vLLM while driving innovation in open-source LLM inference” - Robert Nishihara, Co-Founder of Anyscale & Co-Creator of Ray
Explore More
Check out the repo at https://github.com/vllm-project/aibrix and dive into our blog post for an in-depth look at AIBrix’s architecture and key capabilities. For a deeper understanding, explore our white paper on design philosophy and results, and follow the documentation to get started with deployment and integration and join the vLLM slack’s aibrix channel to discuss with the developers.
FAQ
How is AIBrix different from the vLLM production stack?
-
AIBrix is an open source release from Bytedance with a focus on large scale use cases and cloud native solutions. Production stack, managed by UChicago LMCache team, is an open framework that welcomes everyone to extend, experiment, and contribute. You can see the production stack’s roadmap here.
-
AIBrix is an instantiation of what a powerful K8s stack can be and has been in production for the past 6+ months. Production stack is starting from scratch implementation focused on iterating each building block with the feedback and contributions from the community.
-
Production stack’s desired strength is to leverage built-in KV cache-focused optimizations (transfer, blending, routing), especially beneficial in long-context and prefill-heavy workloads. In the near term, production stack plans to leverage components from AIBrix.
Is AIBrix a community driven project?
Absolutely. The purpose of open-sourcing it under vLLM project organization is to open it up for collaboration both with practitioners and researchers. There are many areas of enhancements planned and the core developers believe in the future is open source!
How is AIBrix different from other cloud native solutions such as KServe, KubeAI, and others?
AIBrix offers more native integration with vLLM. By designing with only an inference engine in mind, AIBrix can prioritize features such as fast model loading, autoscaling, and LoRA management.